Node.js ORMs overview and comparison
I believe that ORM is the most important tool for backend development, the tool we spend the most of our time working on a feature, the tool we scold the most, always wanting something better. Here I'm doing a review of 6 popular ORMs to compare and find the best one.
ORM is a library to access the database, a high-level library where you can define models, and relations. Another option is to write pure SQL, and it's a valid option when performance is the biggest concern, but this way is not well suited for dynamic queries.
ORM is needed to make you more productive, to have automatically returned TS types instead of defining them each time by hand, and to make it more safely so you can't accidentally pass a dangerous string into SQL. Ideal ORM allows defining queries and then combining and reusing them to construct more complex queries.
I'll share my experience of working with 6 popular ORMs including knex which is a query builder, I won't retell the docs and it's not a usage guide, just sharing the experience of how it was easy or difficult to use the ORM on a close to reality project. I'll do benchmarks in the end.
Not touching the topic of migrations here, with any ORM it's possible to use its own migration tools or to use standalone libraries for this. In my opinion, this is a must to have up and down migration for every table and every schema change, so if I used Prisma which doesn't have it, I would use a separate library for migrations together with it. Basically, that's what I did when developing API for this article.
To get a real-world feel of the ORM, I have used realworld API spec, and implemented the same API of the blog site again and again with each one.
The most complex endpoint is GET /articles, the response should include:
columns of article
tag list of articles, via "has and belongs to many relation" between Article and Tag
count of
favorites, each user can mark an article as a favorite, also via "has and belongs to many"favorited - boolean if current user marked as favorite or not, false if not logged in
profile of the author
profile of the author must include
followingfield - boolean to know if the current user follows the author, false if not logged in
Also quite tricky was the endpoint for creating an article, user can provide a tag list for the article, and then in the code, I have to check if the such tag exists, if not need to create the tag, and connect the tag to the new article, and do all of this in a single transaction.
All of the code is published on github.
Not included in the overview:
bookshelf, waterline, OpenRecord: seems to be obsolete, no TS support
deepkit ORM: it hacks typescript compiler, I tried it and wasn't able to manage setup
kysely: actually it looks interesting and worth a try, but it lacks good documentation, so it's complex to write complex queries with it
Raw SQL: too hard to implement this specific API because queries are constructed on the fly, and with Raw SQL it would be too hard and messy to implement.
Sequelize
tldr; Sequelize is very difficult to work with, coming across issues all the time, TS support is poor, and requires lots of boilerplates. Kinda works. It is actively developing lately, perhaps things will get better in the future.
Code examples:
Setup
Sequelize has a default behavior that may be unwanted, so when configuring the main Sequelize instance need to turn this behavior off:
export const db = new Sequelize(config.dbUrl, {
logging: false,
define: {
freezeTableName: true, // with `false` default Sequelize will transform table names
timestamps: false, // by default every model will implicitly have `updatedAt` and `createdAt` columns
},
});
Modeling
I started writing the code for this article in 2020, but now writing models in Sequelize is not so bad. Here I'm leaving the code as it was. In recent versions of Sequelize they try to make modeling similar to how it's done in TypeORM/MikroORM.
Sequelize offers the most bloated way to define a model, first define a TS type:
type UserType = {
id: number
// ...
}
Then define the type of create parameters:
type UserCreate = Optional<User, 'id'>;
Then define the model:
export class User
extends Model<UserType, UserCreate>
implements UserType {
id!: number;
// ...
}
Then define columns with JSON, table name and Sequelize instance:
User.init(
{
id: {
type: DataTypes.INTEGER,
autoIncrement: true,
primaryKey: true,
},
},
{
tableName: 'user',
sequelize: db,
}
}
And then define relations:
User.hasMany(UserFollow, {
as: 'followedBy',
foreignKey: 'followingId',
});
Each column is defined three times: in the type, in the model and in the column definition, it doesn't have to be this way.
Querying
During developing the API with Sequelize I jumped across open issues on Github quite often, here for an example: Can't include "has-many": issue Draw attention to how old is this open issue. So with Sequelize you will have N+1 problem, in my case, it means that for each article it will perform an additional query to load tags.
To query articles by the tag I tried to use belongsToMany relation:
// In Article model:
Article.belongsToMany(Tag, {
as: 'tags',
through: ArticleTag as any, // any because ArticleTag is not accepted without a reason
foreignKey: 'articleId',
otherKey: 'tagId',
});
// in ArticleTag model:
ArticleTag.belongsTo(Tag, {
as: 'tag',
foreignKey: 'tagId',
});
// querying:
Article.findAndCountAll({
include: [
required: true,
model: Tag,
as: 'tags',
]
})
Which gives the error: column ArticleTag.id does not exist.
Second attempt to join article to tags explicitly in calling site:
// Article model:
Article.hasMany(ArticleTag, {
as: 'articleTags',
foreignKey: 'articleId',
});
// ArticleTag model:
ArticleTag.belongsTo(Tag, {
as: 'tag',
foreignKey: 'tagId',
});
// In service:
Article.findAndCountAll({
include: [{
required: true,
model: ArticleTag,
as: 'articleTags',
include: [
{
required: true,
model: Tag,
as: 'tag',
},
],
}]
});
This gives the error: 'missing FROM-clause entry for table "articleTags"' Probably it is related to retrieving count.
So the final working version is to use raw SQL in where:
import { Sequelize, Op } from 'sequelize'
Article.findAll({
where: {
[Op.and]: Sequelize.literal(`
EXISTS (
SELECT 1
FROM "articleTag"
JOIN "tag"
ON "articleId" = "SequelizeArticle"."id"
AND "tagId" = "tag"."id"
AND "tag"."tag" = '${params.tag}')
`);
...otherWhereClauses,
},
include: includes
})
Sequelize was not designed to use with TypeScript, so it is not guilty that writing models is very verbose, or that sometimes I had to write as any to make it work.
Inserting
Inserting and updating is alright, it even has .findOrCreate for simplicity.
There is one gotcha to be very careful with when you're working with a transaction:
await ArticleTag.create(
{ articleId: article.id, tagId: tag.id },
{ transaction },
);
- it's very easy to forget the second argument with
transaction, I was developing a large project with Sequelize and was encountering this mistake many times. So it works fine, seems like not a problem at all, but in a specific situation, part of the records will be rolled back with the transaction, and some of them will be saved. Writing tests is a must on serious projects, and testing a real database, only by writing tests I could find missing{ transaction }options.
TypeORM
tldr; Problematic, very verbose, most of the time is spent on fighting with the ORM. Defining models is easier than with Sequelize, TypeORM is shipped with its own query builder so it's more flexible than Seqeulize, with fewer hacks.
Code examples:
Setup
Setup is straightforward, define a DataSource with a db config and use it everywhere to perform queries.
Modeling
Works just fine, no gotchas.
Querying
TypeORM offers two ways to fetch data: to use it as ORM similar to Sequelize, or to use its own query builder.
For blog API I've been using its query builder almost all the time because the main interface or TypeORM covers only basic queries.
One of the purposes of the ORM is to define relationships, i.e in my case to define that Article is connected to Tag via middle table ArticleTag by matching articleId and tagId columns. Idea is to define this just once and then use it without repeating it. Unfortunately, no way to use it in TypeORM with sub-queries, I had to explicitly define the relationship right in the query:
// select tagList
const tagListSubquery = query
.subQuery()
.select('"tag"."tag"')
.from(Tag, 'tag')
.innerJoin(
ArticleTag,
'articleTag',
// in a good ORM I should not have to write this:
'"articleTag"."tagId" = "tag"."id" AND "articleTag"."articleId" = "article"."id"',
);
I found a problem with the query builder: it is selecting fields not the way I want, here is a sample output:
{
article_id: 19,
article_authorId: 1,
article_slug: 'slug-19',
...other article fields
author_id: 1,
author_email: 'email-1@mail.com',
...other author fields
...etc
},
If you try to join one-to-many relations, such as tags, it will result in repeating article records with different tags:
[
{
article_id: 1,
...article fields
tags_id: 1
tags_name: 'tag 1'
},
{
article_id: 1, // the same id
...article fields
tags_id: 2
tags_name: 'tag 2'
}
]
Converting this response to the desired one would be too tedious, so I decided not to use a query builder.
To resolve the problem from above I tried to use the ManyToMany relation instead of OneToMany and it kinda works:
@Entity()
export class Article implements ArticleType {
// ...columns
@ManyToMany(() => User)
@JoinTable({
name: 'userArticleFavorite',
joinColumn: {
name: 'articleId',
referencedColumnName: 'id',
},
inverseJoinColumn: {
name: 'userId',
referencedColumnName: 'id',
},
})
favoritedUsers?: User[];
}
But there is one downside of it: each article now has to load ALL favorited users, and I check if the current user liked the article on the javascript side.
Let me say it again: instead of loading a simple boolean field from the database, we need to load a bunch of records from two tables to get that boolean.
But later, when I was trying to filter by tag, - it is impossible to do this without query builder.
So I returned to the query builder approach again.
The final approach to resolving real-world app: I used query builder with selecting related records using json_agg and row_to_json from Postgres. I don't even know how it could possible to do that with MySQL.
Inserting
The model doesn't have an automatic constructor, so I had to assign parameters in a bit awkward and unsafe way:
const repo = dataSource.getRepository(User);
const user = Object.assign(new User(), params);
await repo.save(user);
Unsafe because params here possibly can contain unknown key values and TS won't complain about this.
MIkroorm
tldr; similar to TypeORM, takes longer to set up, again it's very problematic to work with, has its own surprises, and has Knex for query builder which is a win.
Code examples:
Setup
Complex to configure. Docs are suggesting to set both entities and entitiesTs, but where should entities point if we don't have compiled output during development? Does it mean we have to compile the project after every change?
const orm = await MikroORM.init<PostgreSqlDriver>({
entities: ['./dist/entities/**/*.js'], // path to our JS entities (dist)
entitiesTs: ['./src/entities/**/*.ts'], // path to our TS entities (source)
// ...
});
Later I found that it's possible to explicitly provide entities, and it works:
const orm = await MikroORM.init<PostgreSqlDriver>({
entities: [Author, Book, BookTag],
// ...
});
Documentation is not very good: embed search doesn't work, searching only via google.
It was a surprise to find that Mikroorm is translating table and column name to underscore case, as I have all tables and columns named in camelCase it was a problem.
So when selecting some camelCased field, I received the error no such field, I wanted to select authorId but the error said "no such column author_id"
To fix that I had to define my own NamingStrategy class. That mostly fixed situation, except for table names, though I defined each method of NamedStrategy, camel-cased table name still was translated to underscore.
The way to solve this is to set static tableName on the entity, which doesn't seem to be documented anywhere at all:
@Entity()
export class UserFollow {
static tableName = 'userFollow';
// ...
}
Unline other ORMs, MikroORM requires you to fork EntityManager in the middleware for all requests to use it later. Some people like dependency injection, but I prefer how you can simply import db instance in any other ORM to work with it, less code and no problems.
Modeling
We need to define a constructor in the model, explicitly define arguments and assign them to the entity. I guess it's just the same as in TypeORM, in the case of MikroORM I've added a constructor because docs suggested to do so, and in TypeORM I've used Object.assign(new Model(), params) because didn't see how to do it better in the docs.
@Entity()
export class Article {
@PrimaryKey() id!: number;
@Property() authorId!: number;
@Property() slug!: string;
// ...
constructor(
params: Pick<
Article,
// here is a list of fields required for new record:
'slug' | 'title' | 'description' | 'body' | 'authorId'
>,
) {
// assign all fields to the entity:
Object.assign(this, params);
}
}
Apart from this and from undocumented static tableName modeling is fine.
Querying
Just like TypeORM, for more than basics you have to use the query builder of MikroORM.
MikroORM query builder is a wrapper around Knex, which is a huge plus for me. Here is an example of how to build a sub-query to select article tags, you can see that joining articleTags to tag is done implicitly, which is good, but to join this query to the article it's explicit where condition:
const tagsQuery = em
.qb(Tag, 'tag')
.select(`coalesce(json_agg(tag.tag), '[]') AS "tagList"`)
// must provide alias as a second parameter
.join('articleTags', 'articleTags')
.where({ articleTags: { articleId: knex.ref('article.id') } });
Inserting
We need to instantiate the Article object and .persistAndFlush it:
const article = new Article(params);
await em.persistAndFlush(article);
Because of Unit of Work pattern in Mikroorm, saving to db takes two steps: first .persist which is only marking record to be saved, and then .flush to really write changes. .persistAndFlush the method does both for us.
But here I have a problem: The article has a relation to the User:
@Entity()
export class Article {
// ...
@ManyToOne({ entity: () => User, inversedBy: (user) => user.articles })
author!: User;
}
And when trying to save an article with just .authorId it fails with the error:
Value for Article.author is required, 'undefined' found
Ok, so instead of passing .authorId we can load the whole user record and provide it to the constructor, but in such case, it gives an error that authorId is required.
Ok, then we can provide both .authorId and .author user record. Error again, this time it says that the article has no column author, and this time it is an SQL error.
I give up at this point, just use .nativeInsert method to avoid Unit of Work patter and related issues.
Finally, creating new article code looks like this:
const article = new Article({ ...params, authorId: currentUser.id });
article.id = await em.nativeInsert(article);
When using .nativeInsert we also need to assign returned id to article.
Bulk insert is broken, this code:
const articleTagsToInsert = tagIds.map((tagId) => {
return new ArticleTag({ tagId, articleId: article.id });
});
await em.nativeInsert(articleTagsToInsert);
Throws an error the query is empty, it works when I change this to saving records one by one:
await Promise.all(
tagIds.map(async (tagId) => {
const articleTag = new ArticleTag({ tagId, articleId: article.id });
await em.nativeInsert(articleTag);
}),
);
Prisma
tldr; Prisma is most pleasant to work with, best query interface, and TS support. The grain of salt is it has a limited query interface, for specific advanced queries you'll have to fall back to writing complete queries in raw SQL. One year ago this "Next generation ORM" could not even handle transactions, so I am very suspicious of Prisma. But now the transactions feature is in preview and overall my experience with Prisma was highly positive. Try it and most likely you'll enjoy it, especially on smaller projects, though I would not be confident to use it in a large long-running projects yet.
Code examples:
An interesting fact about Prisma, it launches a separate server under the hood written in Rust. The main node.js program is sending queries encoded with GraphQL to the Rust server, Rust server calls db and sends results back to the node.js server.
Setup, modeling
The setup is easy. Defining schema in custom DSL language, and having it in a single file is very pleasant. So you can open a single file and easily see all table definitions, and all relations.
Some features of Prisma are currently available "in preview", which means need to specify a feature name in client section of the schema:
generator client {
provider = "prisma-client-js"
previewFeatures = ["interactiveTransactions"]
}
After changing the schema run prisma generate in console.
I've found one gotcha with time stamps when I define fields in this way:
model article {
...skip
createdAt DateTime @default(now()) @db.Timestamp(6)
updatedAt DateTime @default(now()) @db.Timestamp(6)
}
Prisma will serialize dates in the current time zone, and this is unexpected because all other ORMs are saving date in UTC time zone.
To fix this behavior need to set the time zone to UTC in the code:
process.env.TZ = 'UTC';
Querying
I was really excited about how good this part is, really a great job on the query interface! Despite I am skeptical about Prisma, I was able to code all my quite complex queries without a need to fallback to passing raw sql.
So my feeling about this is dual.
On the one hand, Prisma offers the simplest way to perform queries, with the best TS support, and I must admit it's quite powerful, selecting related records is well worked out and quite easy to do.
On another hand, there is a limit somewhere. I didn't reach it in this blog API, Prisma offered what I needed. But the limit exists, in my past projects I used specific database features like Postgres full-text search and trigram search, Postgis, and window functions. I don't believe it's possible to cover all database features in a single interface of the ORM, at some point you will want to add just one small piece of raw SQL to a where condition, but Prisma doesn't support this.
Imagine you have a big complex query with lots of conditions, selecting related records, and it's all fine with the Prisma interface. But then someday you need to add just one small condition where custom SQL is needed, Postgis condition, for example, then you have to rewrite all the queries to a raw SQL.
Inserting, updating, deleting
The interface for data modification is very good, it allows the creation or deletes related record right in the single update, you can see examples in the nested writes section of Prisma docs.
In 2021 Prisma received a long waited "interactive transaction" feature (currently in preview), I tested it on various endpoints and it works just fine.
Objection
tldr; It's an ORM built upon Knex to allow defining models and relations between them. Not as good with TypeScript as Prisma, so I had to typecast results to the needed type. But otherwise, I enjoyed using it, easy to use and allows me to build any query. Definitely better than Sequelize, TypeORM, and MikroORM. But unfortunately, it become deprecated and won't be actively maintained in the future, author has switched to developing Kysely.
Code examples:
Setup
Setup of Objection is easy, simply configure Knex and provide a Knex instance to the objection Model.
Modeling
Defining model class is easy. Defining relation looks like this:
static relationMappings = {
author: {
relation: Model.BelongsToOneRelation,
modelClass: User,
join: {
from: 'article.authorId',
to: 'user.id',
},
},
}
Instead of decorators in TypeORM or MikroORM, not a big deal but for me, syntax without decorators feel cleaner.
The objection has a special feature modifiers, here in the Article model I have:
static modifiers = {
selectTagList(query: QueryBuilder<Article>) {
query.select(
Tag.query()
.select(db.raw("coalesce(json_agg(tag), '[]')"))
.join('articleTag', 'articleTag.tagId', 'tag.id')
.where('articleTag.articleId', db.raw('article.id'))
.as('tagList'),
);
},
}
And later I can use it in such ways:
const articlesWithTags = await Article.query()
.select('article.*')
.modify('selectTagList')
So in such a way, we can keep repeated parts right in the model and use them later when building queries. Unfortunately, modify doesn't have TS check and auto-completion, Objection was designed for plain JS and not so good at TS.
Querying
Querying with Objection feels very similar to querying with Knex, and I like it a lot, easy and straightforward. The big bonus of Objection is the ability to define relations in the model and then use it when querying with different methods, for example, query.joinRelated('tag') to join tags.
The downside of Objection is its bad support of TypeScript at the part of the query result type, for example:
const count = await Article.query().count()
Here variable count has a type Article[], because Objection simply uses model type as the result. And we need type cast it to what we want explicitly:
const count = (await Article.query().count()) as unknown as { count: string }
// yes, count is actually an object with string field for count
Inserting, updating, deleting
Just as with querying, I found mutating with Objection very simple to use and powerful.
Knex
tldr; if you know SQL (it's a must if you dealing with the backend) - you know Knex, which means you don't have to read through the docs and learn how it works, just start using it! Simple, maximum support for database features. Downsides: usually result type is any so you have to cast it, which means need to be careful so the query matches the type. This is a query builder, it doesn't contain models or relations. If you'd like to use Knex on a bigger project, need to organize queries in some reusable way so you won't have to write the same relation joins again and again - that would be error-prone.
Code examples:
Setup, modeling
The setup is straightforward. We don't have models at all in Knex so no need to define them.
To define types of schema, you can write special declare module block to tell Knex what tables and columns you have:
declare module 'knex/types/tables' {
interface Tables {
user: {
id: number
username: string
// ...
};
// ...
}
}
And then use it:
const user = await db('user').select('username').first();
Here username will be autocompleted because TS knows fields of the user, but still, you can provide any string to the select so it won't catch typos of fields.
The result in this example will have a proper type Pick<User, 'username'> | undefined, and if you provide some custom SQL to the select the result will be of type any.
Anyway, friendship with TS is not a good part of Knex. You can provide a type in a generic:
const record1 = await db<{ foo: string }>('table')
const record2 = await db<{ foo: string }>('table').select('foo')
const record3 = await db<{ foo: string }>('table').select('custom sql')
Record1 and 2 have types that we provided, but record3 has type any[], perhaps it won't be a problem in many situations, but I relied on custom SQL in select a lot, for instance, to select tagList of article.
So when working with Knex we should expect that usually return type is any[] or any and cast it explicitly to the needed type.
Querying, inserting, updating, deleting
The only downside of Knex is it doesn't have a way to define relations as ORMs do, otherwise, it's just wonderful, interface is very close to SQL, and gazillions of methods.
Knex is translating SQL into JavaScript DSL, and as a bonus, it's providing handy methods to save us some time.
As the result, when working with Knex you think "how would I do this in SQL" and intuitively translate this to Knex, while in the case of other ORMs you have to figure out how this specific ORM is doing this thing, read conversations in github issues, and quite often you may find that ORM lacks the support of the specific feature.
OrchidORM
tl;dr this is the best ORM available for node.js with perfect TypeScript support. It comprises all the best parts of other ORMs and query builders, plus adds additional features. I highly suggest checking on it for yourself, because as I'm the author of it I may be a little biased :)
Code examples:
Setup
To set it up, we need two files: in one file we configure and export db the instance, and in the second file we export a BaseTable - a class to extend other tables from. Having this BaseTable the class allows us to customize columns: we can configure it to return all timestamps as strings, as numbers, or as Date objects, and do similar overrides for all the columns if needed.
Modeling
Columns are defined similarly to Zod schemas (or like Yup, Joi, etc). This gives a short syntax that allows for various customizations, setting validations right in place, and automatically inferred TS types. And no need to run code generation as in Prisma.
Relations are defined nearby.
export class MyTable extends BaseTable {
table = 'tableName'
columns = this.setColumns((t) => ({
id: t.serial().primaryKey(),
name: t.text(3, 100), // min 3, max 100
...t.timestamps(), // adds createdAt and updatedAt
}))
relations = {
items: this.hasMany(() => ItemTable, {
primaryKey: 'id',
foreignKey: 'itemId,
})
}
}
Querying
Orchid ORM offers an interesting mix of a query builder that enables writing complex custom queries, and a higher-level interface partly inspired by Prisma, that makes working with relations very easy. And everything is type-safe, without manual annotations.
Example: here we load articles, and we can see a list of requested article columns followed by a special nested select. In the nested select, we are free to name properties as needed (not like in Prisma where you have to map the result afterward). It has various methods for how to return the data: pluck in the example will return a flat array of values. It has a feature called repositories, so the query can offload complexity to another more specific query, in the example we have userRepo with custom method defaultSelect. It has exists query to load only a boolean from db, not like in Sequelize we have to load a full record to see if it exists. It's possible to have conditions, here if the currentUser variable is set (it is an authorized request) this will construct an inner query to know if the article is favorited by the user, and if not set it will load a plain false value by using raw. In Orchid ORM it's possible to have just a little piece of the query be a raw SQL, unlike Prisma where you need to rewrite a full query for this.
Orchid ORM converts even such a complex query into just a single SQL command, which makes it the most performant of node.js ORMs.
const articles = await db.article.select(
'id',
'slug',
'title',
'description',
'body',
'createdAt',
'updatedAt',
'favoritesCount',
{
tagList: (q) => q.tags.order('tag').pluck('tag'),
author: (q) => userRepo(q.author).defaultSelect(currentUser),
favorited: currentUser
? (q) =>
q.userArticleFavorites
.where({ userId: currentUser.id })
.exists()
: db.article.raw((t) => t.boolean(), 'false'),
},
);
Inserting
By default, create returns a full record, but it can be customized to return only an id or a specific set of columns. Orchid ORM has various nested methods to insert related records together in one place. This side of Orchid ORM is inspired by Prisma, but it's more flexible: allows to have only some of the inserting properties to be a raw SQL.
const id = await db.article.get('id').create({
...params,
authorId: currentUser.id,
articleTags: {
create: tagList.map((tag) => ({
tag: {
connectOrCreate: {
where: { tag },
create: { tag },
},
},
})),
},
});
Benchmarks
I measured how long it takes for each ORM to serve the articles endpoint (as in API spec of "real world app"), and each request returns 100 articles with tags, author, and other nested fields. Performed 300 such requests per ORM to compare total time:
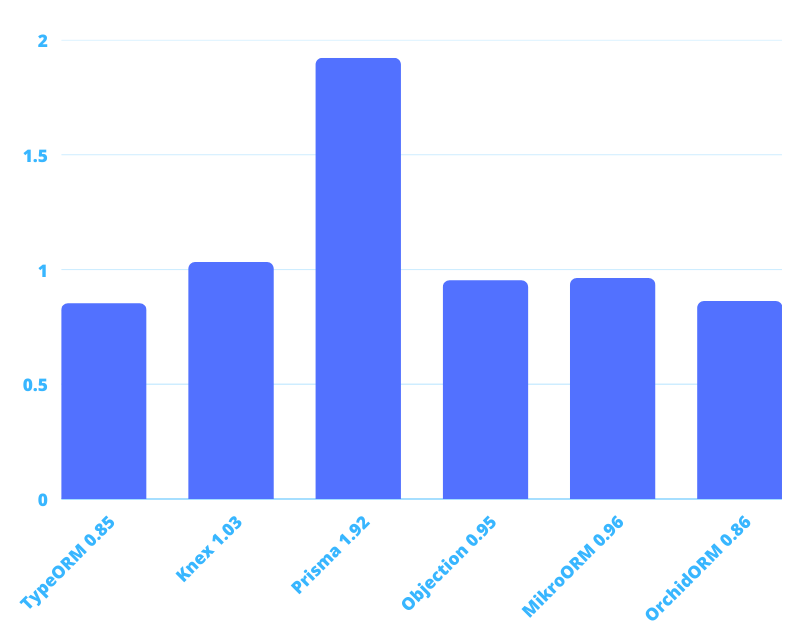
(Sequelize is not included in this chart because it's too slow for comparison)
Slow to fast:
Sequelize: 8.62s
TypeORM: 0.85s
Knex: 1.03s
Prisma: 1.92s
Objection: 0.95s
Mikroorm: 0.96s
OrchidORM: 0.86
Sequelize is the slowest for two reasons: it's indeed the slowest and you can find the same conclusion in other benchmarks over the internet, and also due to its limited interface I could not figure out how to avoid the "N+1" problem, so it performs a separate query for each article to get tags. For other ORMs, there is no N+1.
Prisma is the second slowest. Under the hood, it performs a separate request for each relation, so when we load articles with tags and author it loads articles, then tags, then author - 3 queries. In other ORMs, I was able to load the whole result with just one query. The second reason is overhead, under the hood Prisma is communicating with the database through its own server written in Rust, this server is a middleman between node.js and the database, and other ORMs don't have a such middleman.
For other ORMs, I was surprised to see there is no big difference, almost the same time.
The next thing to know is how fast they can insert. Measured creation of 1000 articles with 5 tags each:
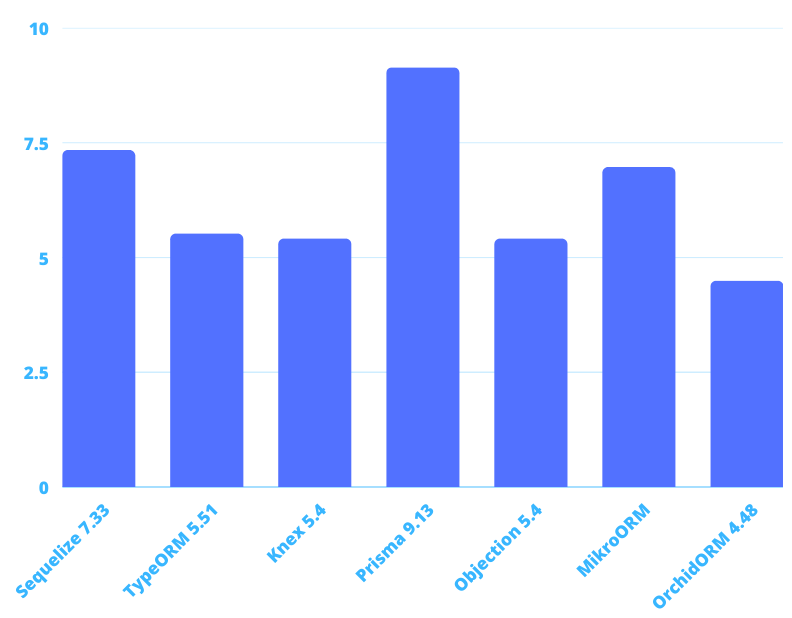
Sequelize: 6.65s
TypeORM: 5.2s
Knex: 4.43s
Prisma: 6.77s
Objection: 5.58s
MikroORM: 7.13s
OrchidORM: 4.48s
Sequelize, Prisma, and MikroORM are a bit slower, but in my opinion, the difference here is negligible.
Conclusion
Which ORM to take for your next project? I've spent a lot of time here finding out the answer. But there is no answer. Each ORM in node.js is another way of pain.
Ironically, the most popular Sequelize was the biggest struggle to use and the slowest. If you want to choose it for the next project - choose anything else. Anything.
TypeORM and MikroORM - with these two I constantly had issues, and experienced unexpected behavior. Can't recommend them.
Bad TypeScript support of Knex and Objection can be compensated with writing tests, DX is suffering of course, but they are bearable. I would prefer Objection since it has models and relations.
Prisma has really nice TS support and makes it easy to query relations, has sweet nested creates, and updates. My experience with this API was highly positive. I was skeptical about it before, it gained the support of long-running transactions only in 2021 which is ridiculous. But now it became a mainstream choice and is slowly but steadily gaining the support of requested features. If the performance of queries is not necessary, and the ability to customize queries is not required - Prisma is a good tool for the job. As a compromise, some people use Prisma as the main ORM and a standalone query builder (or raw SQL) for specific queries.
One popular response I hear from the community: it's normal that ORM covers basic CRUD, and when you go beyond that, just use raw SQL or a query builder. And I really want the community to change minds about this, this doesn't have to be so. I was a ruby developer and developed complex apps with complex queries, and there wasn't a single time when I was restricted by the ORM. Because proper ORM is designed so it's easy to do basic things, it has thousands of methods for different cases to make your life easier, it's built upon query builder which allows writing any possible query, and it allows you to put a piece of SQL when needed, and it's designed to be easily extended. If in ruby they had such ORM for decades, I don't understand why it is not possible to do in node.js with proper TS support. And I believe it's only a question of time, if not now, maybe in a year, or two.
Orchid ORM update: now I'm developing such ORM, and it shows that type safety, flexibility and simplicity of usage are achievable together!